paper
[논문리뷰] LLaVA : Visual Instruction Tuning
jaeha_lee
2025. 2. 12. 21:40
Visual Instruction Tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, Yong Jae Lee
NeurIPS 2023
[https://arxiv.org/abs/2304.08485]
Contents
1. ChatGPT
1-1. GPT-1
1-2. GPT-2
1-3. GPT-3
1-4. GPT-4
1-5. Instruct GPT
1-6. RLHF
2. LLama
3. Gemini
4. DeepSeek
5. LLaVA
5-1. LLaVA - https://jaeha-lee.tistory.com/93
5-2. LLaVA-Next
5-3. LLaVA-NeXT-Interleave
6. LoRA

Summary
- Visual Instruction Tuning을 통해 LLM을 Multimodal 모델(img & language) 로 확장하는 방법을 제시
- ChatGPT/GPT-4를 사용하여 이미지-텍스트 쌍을 적절한 instruction-following 형식으로 변환하는 데이터 재구성 관점과 파이프라인을 제시
- CLIP encoder와 Vicuna의 language decoder를 연결하여 end-to-end로 학습할 수 있게 함
- LMM prompt tuning에 생성된 데이터를 사용하는 효과를 검증하고, 범용 instruction-following visual agent 를 구축하기 위한 실질적인 팁을 제시 → VLM 제시했다 ~ 이런 느낌
- Multimodal instruction-following benchmark 제시
- 기존 VLM 모델의 경우 특정 작업에 특화되어 있는 하나의 작업만 가능 -> LLaVA는 다양한 기능 한번에 end-to-end로 가능
- 예를들어, 이미지 보고 길을 찾는 테스크 딱 하나만 가능 나머지 task는 불가 - visual instruction tuning의 경우 모델이 얼마나 instruction을 잘 따르는지
- visual prompt tuning은 모델 adaptiation parameter-efficiency를 향상 시키는 것을 목표로 함
* Visual instruction tuning - LLM이 이미지를 이해하고, 이미지와 관련된 질문에 답변하고, 이미지에 대한 설명을 생성하는 등 다양한 작업을 수행할 수 있도록 훈련하는 것을 의미
* general-purpose instruction-following visual agent - 사람이 일상적인 언어로 지시한 다양한 작업을 이미지를 보면서 수행할 수 있는 시스템
Method
Data

- 모델 학습에 필요한 multimodal instruction-following 데이터를 생성하는 방법을 설명함
- 기존에는 이러한 데이터가 부족함
- 생성과정
1) 위에 그림에서 이미지 관련해서 할 수 있는 질문을 GPT-4를 통해 생성함
2) 기존 caption과 bounding box 정보를 활용해, 1)에서 생성한 질문을 가지고 적절한 대답을 생성함
3) GPT-4를 활용하여 3가지 유형의 instruction-following 데이터를 생성함 → 질문에 대한 답변들을 생성함
- 대화 : 이미지에 대한 질문과 답변으로 구성된 대화를 생성함
- 상세 설명 : 이미지에 대한 자세한 설명
- 복잡한 추론 : 이미지를 보고 심층적인 추론이 필요한 질문과 답변을 생성함 - 그 결과 총 158,000개의 language-image instruction-following 샘플을 수집함
구조


- pretrained LLM + visual model 사용
- LLM 부분은 vicuna 사용
- visual encoder - CLIP ViT-L14 + 마지막 transformer layer 이전과 이후에 grid feature도 고려함
- linear layer - 이미지 fetaure를 word embedding 공간과 연결하기 위해 사용 (위에 식 적기)
- projection matrix W를 사용하여 이미지 feature Z_v를 단어 임베딩 공간과 동일한 dimension을 가지게 H_v로 변환함

- 각 이미지 X_v 에 대해 여러 턴의 대화 데이터 (X_q1, X _ a1,..., X _ qT, X _ aT) 를 생성함

- 수식 설명 → 이미지와 텍스트 질문을 입력으로 받아 올바른 텍스트 응답을 예측하는 확률
- X_v : 입력 이미지
- X_instruct : 사용자의 질문 (text instruction)
- X_a : 모델이 생성해야 하는 정답 (text response)
- L : 응답 X_a의 길이 (생성해야 하는 텍스트의 토큰 개수)
- : i번째 토큰 x_i가 나올 확률을 예측하는 모델 θ
- x_<i : i번째 토근 이전에 생성된 모든 토큰
- 길이가 L인 sequence에 대해 답변 Xa 대한 확률
- θ는 훈련 가능한 parameter, 앞에 나온 단어들을 보고 다음 단어를 맞춤, 기존 방법들과 달리 이미지 feature를 함께 사용함
- 이미지들이 모든 답변들에 대해서 grounded 됐다는 것을 강조하기 위해 X_v 명시적으로 표기
- 초록색 부분에 해당하는 token을 예측하도록 학습함 (즉, 항상 가장 높은 확률로 나오게 끔)
학습 방법
Stage 1- feature alignment 를 위한 pretrain
- visual encoder와 LLM 가중치를 모두 고정하고 훈련 가능한 parameter, θ=W(projection matrix)만 사용하여 위의 식 가능성을 최대화
- 학습 결과 H_v를 LLM feature와 alignment 가능
Stage 2 - End-to-End Fine-tuning
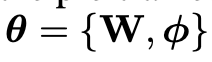
- visual encoder는 계속 고정하고 LLaVA에서 proj layer와 LLM의 pretrain weight를 계속 업데이트
- trainable parameter -> θ={W, φ}
Experiment
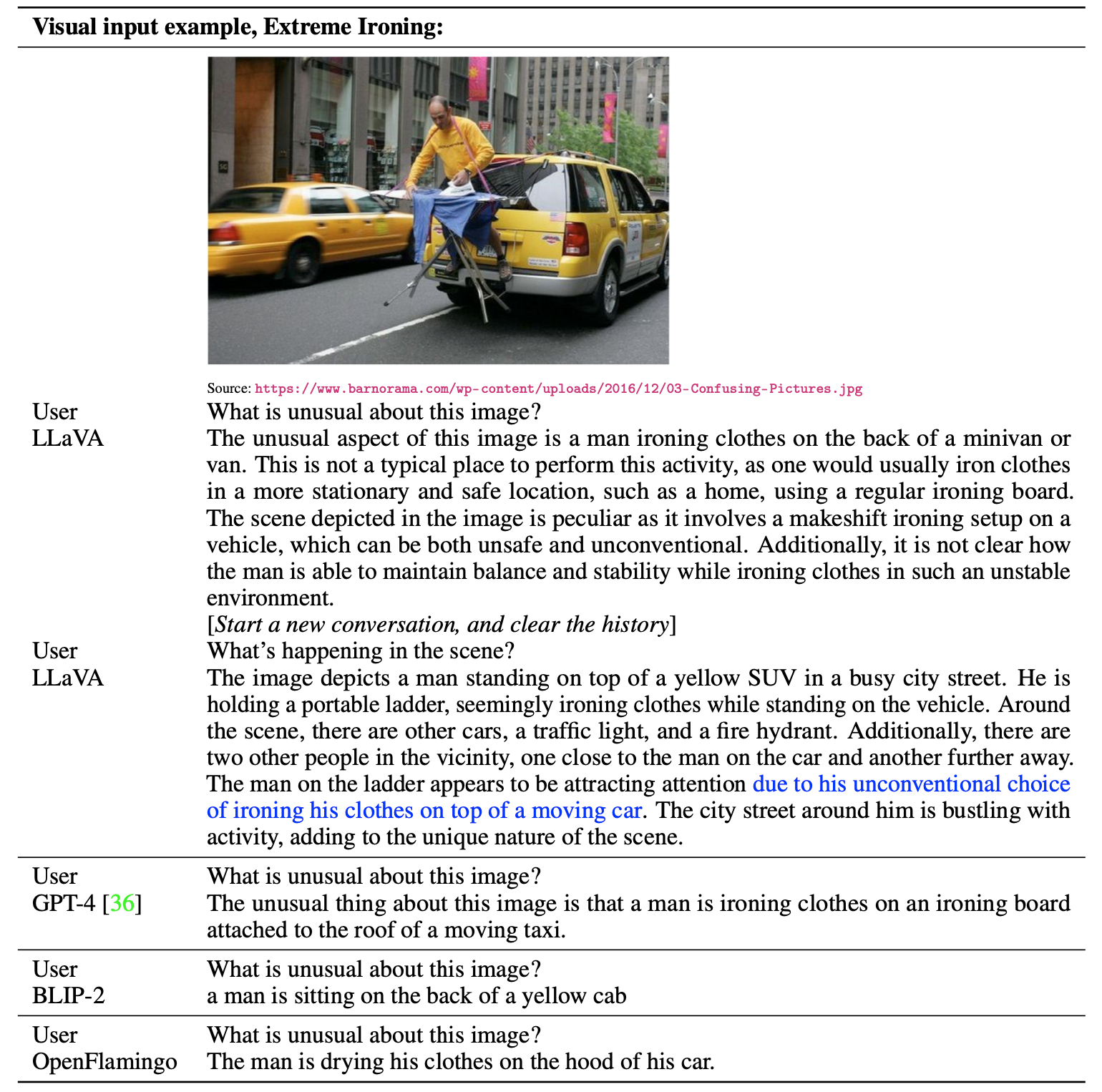
- LLaVA는 단순히 장면을 설명하는 대신 사용자의 질문에 정확하게 따랐고, GPT-4보다 더 포괄적인 답변을 제공
- ScienceAQ - LLaVA가 마지막 레이어 이전의 시각적 특징을 사용하고 먼저 이유를 예측한 다음 답변을 예측하도록 훈련하여 90.92%의 정확도를 얻었으며, 이는 SoTA인 91.68%에 매우 근접한 결과
Ablation
- visual feature
- CLIP 마지막 레이어 특징을 사용했을 때, 마지막 레이어 이전 특징을 사용했을 때보다 정확도가 0.96% 감소함
- 이는 CLIP의 마지막 레이어 특징이 이전 레이어보다 global하고 abstract한 이미지 속성에 더 중점을 두기 때문 - chain of thought
- reasoning보다 answering을 먼저하여 학습하는 것이 더 효과적임
- 예를 들어 어떤 의자 사진이 있고 그 의자는 뭘로 만들어졌을까? 에서 답을 바로 하는 것이 answering. 흔들 의자는 일반적으로 튼튼한 재료로 만들어지며, 나무는 의자를 만드는 데 일반적으로 사용되는 재료이기 때문에 나무이다. 하는 것이 reasoning - pretrain 없이 학습을 하면 오히려 정확도가 떨어짐 -> pretrain 중요성
- 파라미터가 많을 수록 효과적
Conclusion